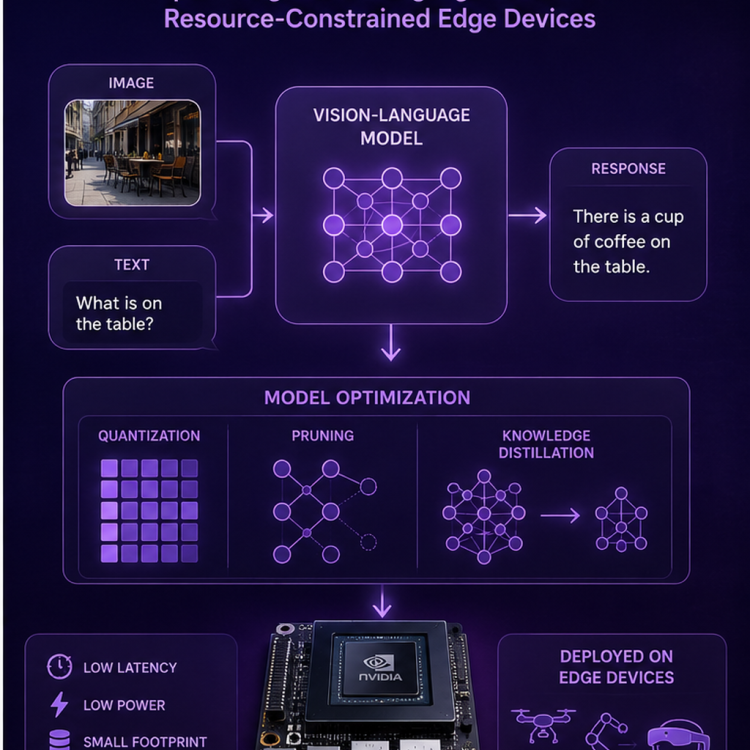
In EdgeVLMOpt (EVO): Optimizing Vision-Language Models for Resource-Constrained Edge Devices, we aim to develop efficient and scalable techniques to enable the deployment of advanced vision-language models (VLMs) on edge hardware. While VLMs have demonstrated strong capabilities in multimodal reasoning and understanding, their high computational and memory demands pose significant challenges for real-time, on-device applications.
Research projects in Information Technology
Displaying 11 - 20 of 212 projects.

EdgeFusionAI (EFAI): Real-Time Multi-Sensor Multi-Modal Intelligence on Edge Devices
In EdgeFusionAI (EFAI): Real-Time Multi-Sensor Multi-Modal Intelligence on Edge Devices, we aim to design and develop efficient techniques for fusing heterogeneous sensory data, including vision, LiDAR, radar, and other modalities, to enable robust and real-time decision-making on resource-constrained edge platforms. This project focuses on building intelligent systems capable of integrating diverse data sources while addressing the challenges of limited computation, memory, and energy availability at the edge.
Supervisor: Dr Mohammad Goudarzi

Audio captioning using machine learning
This project involves the automated generation of textual descriptions for audio content, such as spoken language, sound events, or music. This process typically employs deep learning techniques, such as recurrent neural networks, transformer models, and so on, to analyse audio signals and generate coherent captions. By training on large datasets that include both audio recordings and corresponding textual descriptions, these models learn to recognize patterns and contextual meanings within the audio.
Supervisor: Assoc Prof Thanh Thi Nguyen
Voice cloning deepfakes detection using machine learning
This project focuses on identifying and distinguishing between authentic audio recordings and those that have been artificially generated or manipulated. As voice cloning technology advances, creating realistic audio deepfakes has become easier, raising concerns about misinformation and privacy. To combat this, this project aims to develop machine learning models to analyse audio features such as pitch, tone, cadence, and spectral characteristics. These techniques are implemented to detect subtle anomalies that may indicate manipulation, even in high-quality deepfake audio.
Supervisor: Assoc Prof Thanh Thi Nguyen
Image-based Landmark Detection and Classification
This project aims to develop a computer vision system capable of detecting and classifying domestic geographic landmarks in images and video content. By categorizing locations such as “childcare centre”, “school”, “shopping centre”, “hotel”, “bus stop”, “train station”, and so on, the system provides a reliable way to identify key landmarks in urban and suburban environments. Using advanced machine learning techniques, the model processes visual data to recognize distinct architectural features, signage, and contextual cues associated with each landmark type.
Supervisor: Assoc Prof Thanh Thi Nguyen
Gait Detection for Anonymous Attribution in Security Systems
This project focuses on developing a gait detection system leveraging computer vision techniques to recognize individuals in security footage, even when their faces and skin are obscured. Criminals often cover their faces to avoid recognition, making traditional facial recognition unreliable. By analyzing key features of an individual’s gait, such as walking style, speed, and direction, this system provides a robust alternative for visual attribution.
Supervisor: Assoc Prof Thanh Thi Nguyen
Simulating Criminal Networks Using Reinforcement Learning and Graph Theory
This project focuses on simulating the organic growth of criminal communication networks by leveraging techniques such as Reinforcement Learning and Graph Theory. The goal is to curate a synthetic dataset that models the evolving structure and dynamics of illegal networks, taking into account factors like social connections, communication patterns, and resource allocation. By using graph-based models, the project aims to create realistic representations of how criminal groups form, expand, and operate under various conditions.
Supervisor: Assoc Prof Thanh Thi Nguyen
Blackbox Optimization of Unknown Functions
In many branches of science (e.g., Artificial Intelligence, Engineering etc.), the modelling of the problem is done through the use of functions (e.g., f(x) = y). On a very high-level, we can think of Machine Learning as the problem of approximating function f from the pair of measurements (x,y), and Optimization as the problem of finding the value of input x that maximizes the output y given function f.
Supervisor: Dr Buser Say
Quantum-Enhanced Learning Analytics for Adaptive Early Intervention in Higher Education
Overview
This project proposes a novel quantum-enhanced learning analytics framework for higher education, focusing on early identification of at-risk students and optimisation of intervention strategies using hybrid quantum-classical approaches. While current learning analytics systems rely on classical statistical and machine learning techniques, they often struggle to capture the complex, uncertain, and multi-dimensional nature of student learning behaviours.
Supervisor: Assoc Prof Anuja Thimali Dharmaratne
Bayesian Uncertainty Estimation for Robust Single- and Multi-View Learning in CV and NLP
Background and Motivation
Modern deep learning models have achieved remarkable success in computer vision and natural language processing. However, they typically produce overconfident predictions and lack reliable mechanisms to quantify uncertainty. This limitation becomes particularly problematic in high-stakes applications, such as healthcare diagnosis, autonomous systems, and scientific discovery.
Supervisor: Assoc Prof Lan Du