Congenital heart disease affects 1 in 100 babies. Spatial gene expression patterns are critical to understand how the heart develops and what underlying genetic patterns are behind heart malformation. High-throughput spatial temporal data have been recently generated with spatial transcriptomics technologies. Capitalising on these rich datasets, we aim to build a custom analysis workflow in which the cells are profiled with precise spatial gene expression information. The student will provide fundamental contribution to of this project, by:
Research projects in Information Technology
Displaying 1 - 10 of 210 projects.

[Malaysia] - Human-Centred Explainable Medical Artificial Intelligence using Large Language Models
Human Centred AI
Recent advances in artificial intelligence have produced highly accurate diagnostic models across a wide range of medical applications. However, these systems often provide little insight into how decisions are made, limiting clinician confidence and adoption in healthcare settings.
Supervisor: Dr Fuad Noman

[Malaysia] - Foundation Models for Graph Representation Learning in Medical Artificial Intelligence
Graph learning has become one of the most successful approaches for analysing complex biomedical data such as brain connectivity networks, molecular interactions, and patient similarity graphs. However, most existing graph neural networks are developed for individual diseases or specific datasets, limiting their ability to generalise across different clinical applications.
Supervisor: Dr Fuad Noman

[Malaysia] - Trustworthy Agentic Artificial Intelligence for Explainable Medical Decision Support Systems
Artificial Intelligence is rapidly transforming healthcare by assisting clinicians in disease diagnosis, prognosis, and treatment planning. While recent advances in deep learning and large language models (LLMs) have significantly improved predictive performance, most existing AI systems remain passive prediction tools that lack transparency, reasoning capability, and reliability. These limitations hinder their adoption in real-world clinical practice, where explainability, trust, and accountability are essential.
Supervisor: Dr Fuad Noman
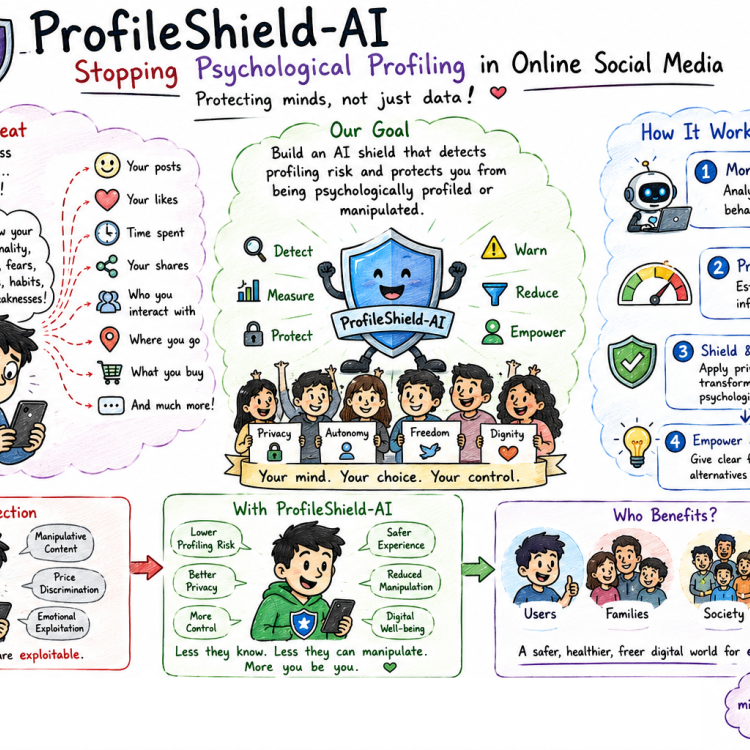
ProfileShield: Preventing Psychological Profiling and Behavioural Manipulation in Online Social Media
Please note that this PhD topic is offered exclusively at our Monash Malaysia campus and is not available at the Clayton campus.
Core PhD Question
How can we prevent AI systems, advertisers, platforms, and malicious actors from constructing psychological profiles of social media users while still allowing meaningful online interaction, personalization, and content discovery?
Supervisor: Dr Sanoop Mallissery
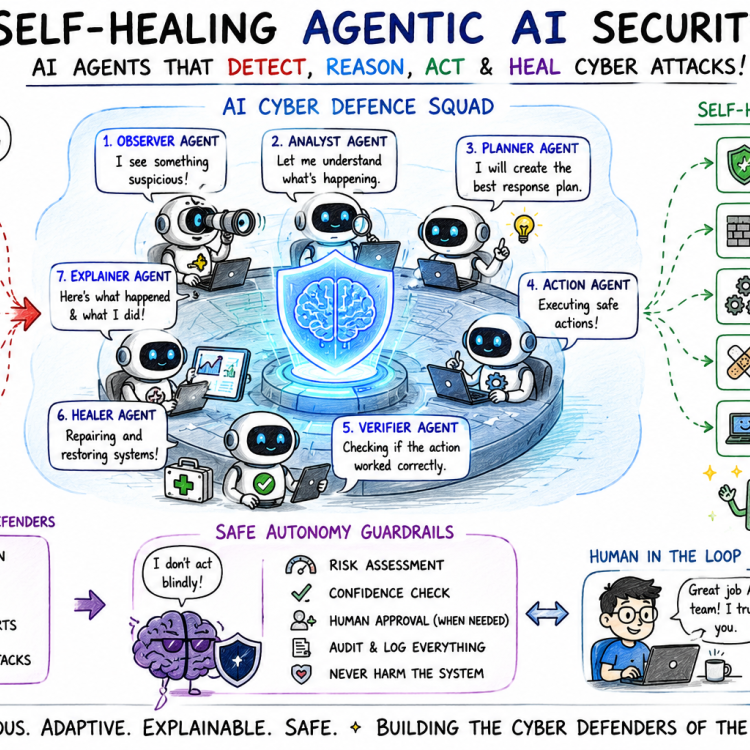
Self-Healing Agentic AI Security: Building Autonomous Cyber Defense Systems for the Post-LLM Era
Please note that this PhD topic is offered exclusively at our Monash Malaysia campus and is not available at the Clayton campus.
Core PhD Question
How can we design autonomous AI security systems that can detect, reason about, respond to, and recover from cyberattacks with minimal human intervention, while remaining safe, explainable, and resistant to manipulation?
Supervisor: Dr Sanoop Mallissery

Cyber-Immune Medical AI: Securing Future Healthcare Systems Against Adversarial, Privacy, and Agentic AI Threats
Please note that this PhD topic is offered exclusively at our Monash Malaysia campus and is not available at the Clayton campus.
Core PhD Question
How can we design future medical AI systems that remain secure, privacy-preserving, explainable, and clinically reliable when exposed to adversarial attacks, prompt injection, poisoned data, privacy leakage, and unsafe autonomous AI-agent behaviour?
Supervisor: Dr Sanoop Mallissery

PatchSentinel-X: Transformer-Based Security Patch Intelligence for Vulnerability Lifecycle Assurance
Please note that this PhD topic is offered exclusively at our Monash Malaysia campus and is not available at the Clayton campus.
Core PhD Question
Can Transformer models understand the full lifecycle of a vulnerability; from vulnerable code, to patch, to advisory, to regression risk; and determine whether a security fix is complete, safe, and trustworthy?
So we are not planning to do the following:
Supervisor: Dr Sanoop Mallissery

Optimisation and Customisation of Biomedical VLMs
Medical VLMs - especially if they can be deployed inside "corporate firewalls" or under the direct governance of health services - potentially offer great advantages over general purpose VLMs for a range of reasons.
However there are fundamental questions over their performance and suitability for deployment inside healthcare, and as to whether they can compete given the mega-infrastructure and ability to upgrade that is available to the big players (OpenAI, Anthropic etc).
Supervisor: Chris Bain
Verifiable, Uncertainty-Aware World Models as Safety Guardrails for AI Agents
The rapid deployment of increasingly capable AI agents has prompted a fundamental reassessment of how safety should be built into AI systems. Bengio and colleagues have argued that purely agentic training objectives are intrinsically risky and have proposed an alternative paradigm: a non-agentic "Scientist AI" that explains the world from observations rather than acting in it, combining a world model that generates explanatory theories with a question-answering inference machine, and operating with explicit notions of uncertainty so as to mitigate overconfident predictions [1].
Supervisor: Dr Lizhen Qu