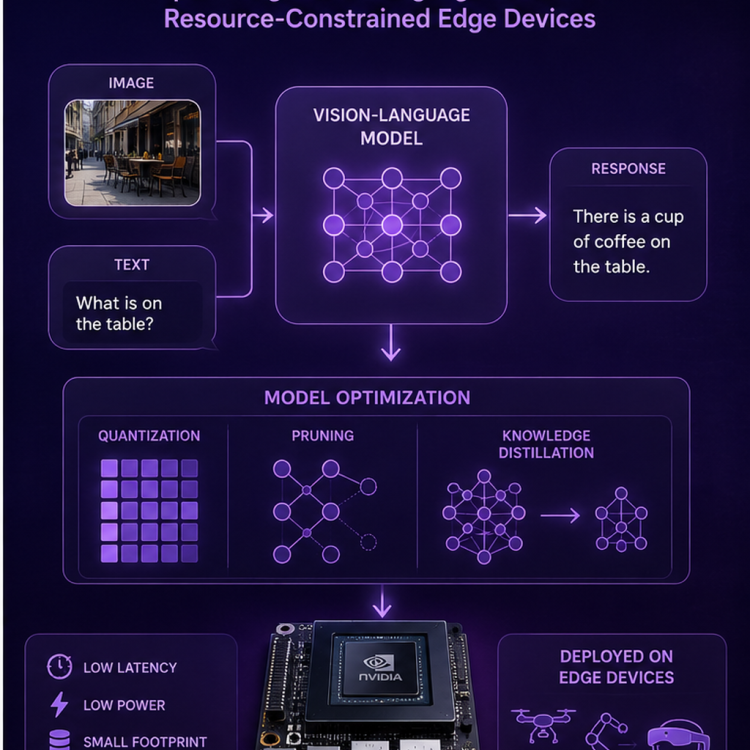
In EdgeVLMOpt (EVO): Optimizing Vision-Language Models for Resource-Constrained Edge Devices, we aim to develop efficient and scalable techniques to enable the deployment of advanced vision-language models (VLMs) on edge hardware. While VLMs have demonstrated strong capabilities in multimodal reasoning and understanding, their high computational and memory demands pose significant challenges for real-time, on-device applications.
Research projects in Information Technology
Displaying 1 - 10 of 38 projects.

EdgeFusionAI (EFAI): Real-Time Multi-Sensor Multi-Modal Intelligence on Edge Devices
In EdgeFusionAI (EFAI): Real-Time Multi-Sensor Multi-Modal Intelligence on Edge Devices, we aim to design and develop efficient techniques for fusing heterogeneous sensory data, including vision, LiDAR, radar, and other modalities, to enable robust and real-time decision-making on resource-constrained edge platforms. This project focuses on building intelligent systems capable of integrating diverse data sources while addressing the challenges of limited computation, memory, and energy availability at the edge.
Supervisor: Dr Mohammad Goudarzi

Hybrid Quantum–Classical Algorithms for Scalable Data Systems and Intelligent Analytics
This PhD project focuses on the design and evaluation of hybrid quantum–classical algorithms for large-scale data analytics and optimisation problems.
The research will investigate how quantum computational techniques can be combined with classical systems to improve performance, scalability, and solution quality for tasks such as:
Supervisor: Prof Aamir Cheema
Enhancing SOC Efficiency: Automated Attack Investigation to Combat Alert Fatigue
Security Operations Centres (SOCs) play a central role in organisational defence and are responsible for continuous monitoring, detecting, investigating and responding to cyber attacks. Organisations increasingly depend on security tools to flag suspicious activity. These tools generate alerts that analysts must examine to determine whether they represent real attacks or false positives. However, the volume of alerts continues to grow at a pace that far exceeds what human analysts can realistically review.
Supervisor: Dr Mengmeng Ge
Generative-AI driven Requirements Regulation in Space Missions
see all the details here: https://careers.pageuppeople.com/513/cw/en/job/687090/phd-opportunity-on-generativeai-driven-requirements-regulation-in-space-missions
Supervisor: Dr Chetan Arora
Designing Secure and Privacy-Enhancing Frameworks for Digital Education Credentials
This project will investigate the security and privacy challenges emerging from the adoption of digital education credentials, such as W3C Verifiable Credentials. As universities and employers increasingly rely on digital systems to issue, store, and verify qualifications, new risks arise—ranging from data breaches and identity fraud to profiling and surveillance through credential verification logs.
Supervisor: Dr Hui Cui
Testing AI/LLM systems
In this project, we will develop automated approach to detect the defects in AI systems, including LLMs, auto-driving systems, etc.
Supervisor: Dr Yongqiang Tian
Automated software testing and debugging with/without LLMs
The objective of this project is to design automated approach to detect bugs in various software, e.g., compilers, data libraries and so on.
The project may involve LLMs.
Supervisor: Dr Yongqiang Tian
Development of a GIS-Based Model for Active Citizenry
Development of a GIS-Based Model for Active Citizenry
Supervisor: Prof Aamir Cheema
Street-Level Environment Recognition On Moving Resource-Constrained Devices
Street-Level Environment Recognition On Moving Resource-Constrained Devices
Supervisor: Prof Aamir Cheema